都知道,无论使用什么框架,神经网络都是非常消耗显存的,那么,这些消耗的显存到底保存了什么?
从一个例子开始
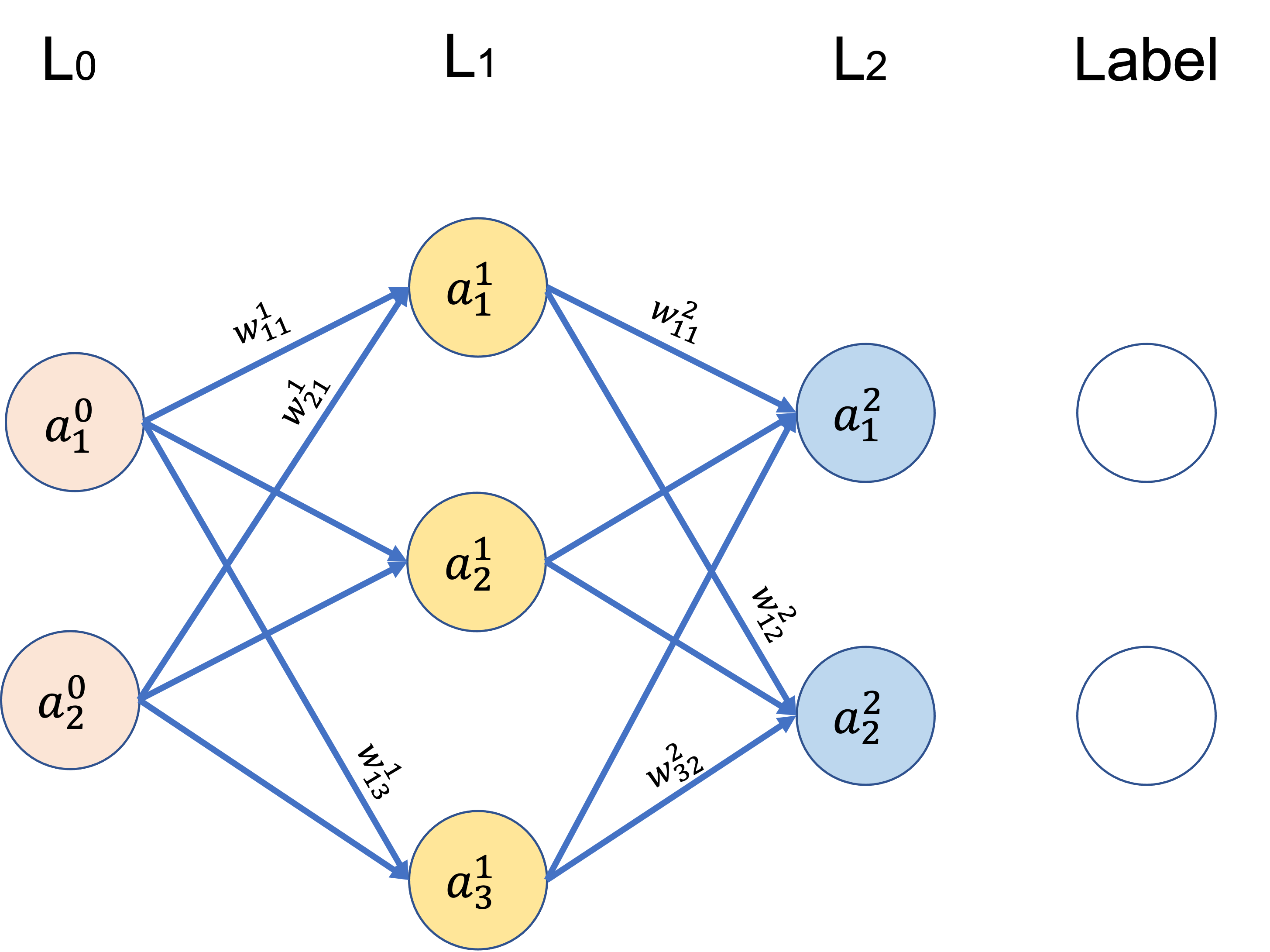
标注解释:
$z_i^k$:第$k$层第$i$个$feature$的输出(不经过激活函数))
$a_i^k$:其值为$g(z_i^k)$,$g(x)$为激活函数,这里把输入层数据$x_i$看作第0层。
$w_{ij}^k$: 从第$k-1$层到第$k$层的传播权重
这里去掉了偏置权重$b$
正向传播:
反向传播
假设损失函数为MSE损失:
下面开始计算对各个参数$w_{ij}^k$的偏导。
从最近的开始:
由公示(6)(7)可以总结出来:
其中$a_i^{k-1}$在正向传播中已经算出,下面计算$\frac{\partial L}{\partial z_j^k}$:
由(9)(10)可知,要求得$\frac{\partial L}{\partial z_j^k}$,需要$w_{ij}^k$和$z_i^k$。
总结
$\qquad$现在可以得出结论,在整个神经网络训练过程中,出于反向传播的需要,我们需要在正向传播的时候在显存中记录$a_i^k$、$w_{ij}^k$和$z_i^k$。但是由于我们常用的激活函数都是可逆的,即知道$a_i^k$能反算出$z_i^k$,因此也可以只保存$a_i^k$、$w_{ij}^k$。

