研究意义
对话问题是NLP领域一个常见问题,重点研究如何让用户和机器进行顺畅的交流,从功能上可分为任务式对话、聊天式对话对话。目前研究任务型对话相对较为成熟,当前市面产品例如苹果Siri、微软Cortana、百度小度等等在完成用户指令方面都比较出色,显现了对话系统极大的潜力,但闲聊问题比较复杂难度较大,但事实上大多数人类的对话都会集中在闲聊、社交、个人情感上,比如在推特上80%都是关于个人情感、想法。因此针对该问题的研究很有价值。
对话问题从领域上可分为开放领域对话和基于知识对话,当前开放领域研究较多,常见手机聊天软件也都是开放领域,虽然此类对话系统对也可以很好的满足人们的一些常见情感需求,但是却有很大的限制,例如:Q:儿子,你不要娶了媳妇忘了娘呀!A:放心,我会一直娘下去的。之所以Agent会给出这样的回答是因为没有”娶了媳妇忘了娘”这句俗语的背景知识。如果对话系统有这种学习能力,其作用会更加广泛,例如让掌握商品情况,然后User对其提问Agent自动回答实现自动化购买,甚至给出教材让Agent模拟教师备课,由Agent提出有意义的问题和学生对话,同时检测学生的知识掌握情况并提出指导性建议。
因此,基于知识的对话研究非常有必要,本课题拟所涉及到的的是多模态的知识,因为学习的内容一般不仅仅包含文字,同时也少不了图像、视频等,这些都对模型学习背景知识提供很大的帮助,该领域常被称为Knowledge Grounded Conversation (KGC),旨在研究对于一定的知识背景,User和Agent根据其内容进行多轮对话,同时Agent的每次回答不仅会考虑User的提问以及对话历史,还会考虑文档内容,但是对于开放领域的知识会较少考虑,可以看做增添额外的信息与约束的对话生成。
研究现状
对话系统从NLP起步阶段就一直是热点问题,从模型角度讲可以分为两大类别:检索式和生成式,检索式对话是一种比较经典的方式,将对话问题抽象为搜索问题,先经过query理解,然后进一步进行召回、排序,等人在Multi-view Response Selection中认为在对话模型中将单词作为单元很难捕捉到话语层面的信息和依赖关系,因此提出了一种多视图响应模型,将单词级别和话语级别进行联合建模。 等人在SMN中认为全部话语拼接是不利的,并且在抽象的高层语义中直接匹配是不可取的,因此提出当前回应和每个历史话语分别匹配,再过交替CNN和MaxPooling,最后RNN累积匹配信息的处理方法和流程。等人在DUA中对SMN进一步改进,提出用最后一个话语来区别前面历史话语中词重要程度的方式。针对生成式对话生成中,Iulian V. Serban等人建议训练时考虑让答复引入新信息(Deep Reinforcement Learning for Dialogue Generation),保证语义连贯性等因素, 等人提出一种多层生成式模型(Building End-To-End Dialogue Systems Using Generative Hierarchical Neural Network Models),利用层级RNN把之前多轮对话背景加以考虑。等人认为,对话里面的句子一个是token等局部特征组成了句子级别的特征,另外一个是存在于句子之间的隐藏特征,为了利用这些隐藏特征,作者提出了一种包含隐藏变量的神经网络生成模型,并利用了VAE的生成能力来编码隐藏变量。
除了开放领域的对话生成,基于知识的对话生成也是近些年研究热点,针对背景文档过长的问题,等人提出TMN模型,从文档中筛选关键句子然后以学习这些句子来建模,等人提出GLKS,模型在对输入信息(对话和文档)进行交互后采用一种全局指导局部的思路,使用对话历史从文档中筛选出重要的n-gram信息来指导后续的生成过程。由于背景知识大多不只有文字,还有图片等等,只用文字必然会损失信息,因此多模态对话也是当前一个研究热点,等人在OpenViDial中提出三种模型,分别通过纯文本、粗粒度视觉信息、细粒度视觉信息的对比,证明视觉对对话任务的增强作用。有等人提出Maria模型,该模型包含三个组件:图像检索模型、视觉概念检测模型和基于视觉知识的对话生成模型,利用三个组件检索出的视觉信息增强对话知识(Maria: A Visual Experience Powered Conversational Agent)。等人提出一种响应驱动的视觉状态估计器,通过响应驱动的注意力更新以及视觉信息的条件融合机制分别增强语言编码能力和视觉融合能力(Answer-Driven Visual State Estimator for Goal-Oriented Visual Dialogue-commentCZ)。
研究难点以及拟解决方案
数据集严重匮乏
本课题拟研究多模态背景知识下多模态的对话,当前相关数据集大多是广泛领域的对话,基于背景知识的对话数据集并不多,仅存在的几个数据集例如CMUDoG、Movie-chats、Persona都是完全基于语言的数据集,最近的OpenViDial虽然背景知识是多模态,但对话内容完全基于语言,因此首要问题是数据集的创建。
多模态知识的有效利用
和开放领域的对话不同,本课题的对话需要基于背景知识,因此如何让生成的对话仅仅围绕所给背景知识至关重要,例如背景知识是电影简介,对话内容应当围绕电影的情节、角色进行。同时,作为多轮对话模型,不仅仅要考虑到背景知识、当前语句,还需要考虑到上一轮次,而且不同于常见的对话模型,本课题还需要考虑到多模态融合。
本课题拟使用基于pretrain-finetune的方式,其中pretrain阶段可以看作一个多任务的自监督多模态模型,用于学习背景知识,finetune阶段则可以看作对话生成阶段。
pretrain模型类似图示: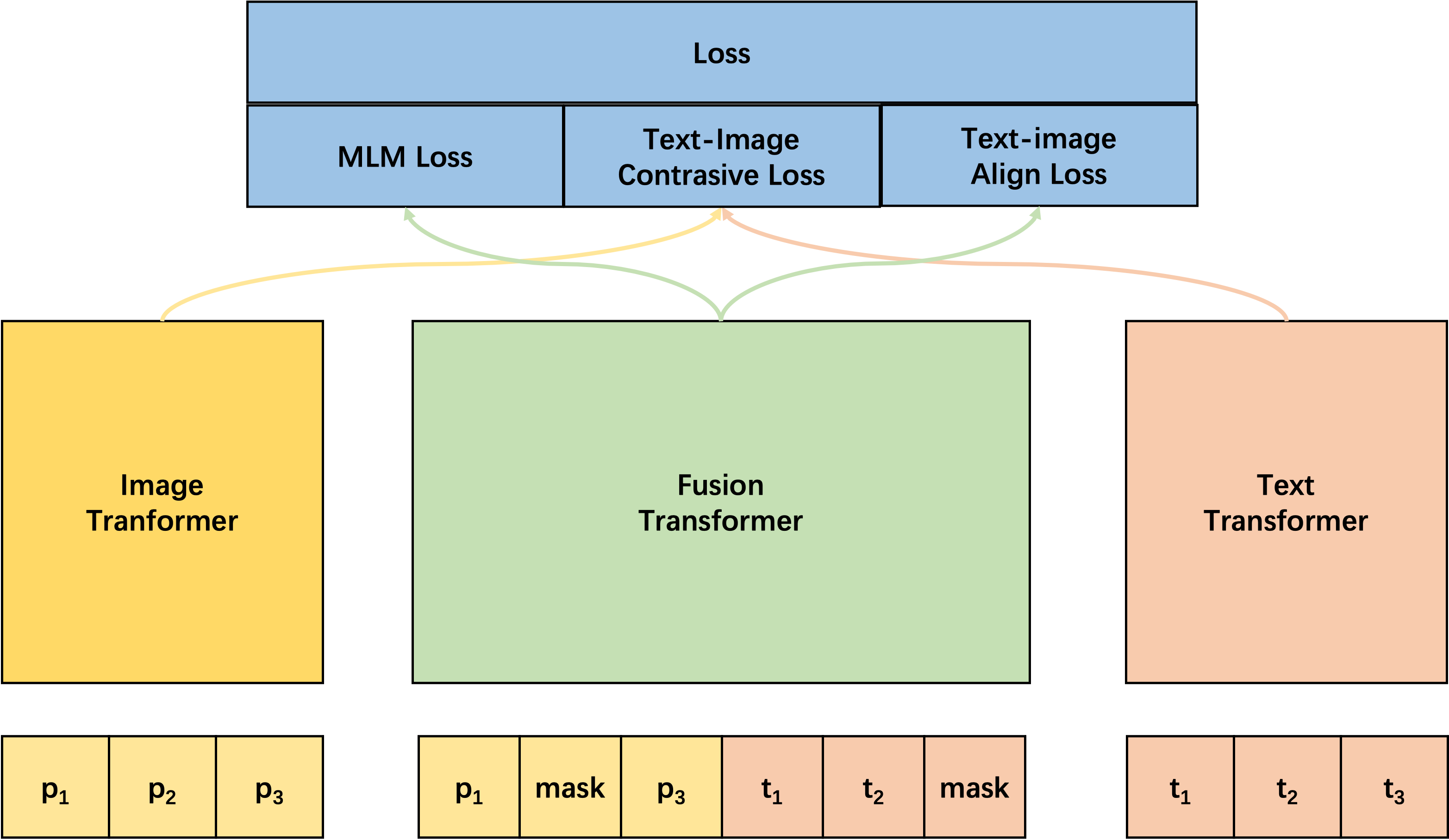
pretrain
该预训练模型包含三种损失函数:- Text-Image Contrasive Loss: Image Transformer的输入是文档中的图片,并将图片分为多个Patch,Text Transformer 的输入是文档中的文字,该Loss相当于有监督对比学习,在同一个训练Batch,只有一组Image和Text来自同一个文档,Batch内其他Image和Text的组合分别来自不同文档。
- Text-Image Align Loss: Fusion Transformer输入序列是整个文档,对于输入数据,随机替换若干Image或Text为其他文档的数据,
MLM Loss: Fusion Transformer的输入包含两种Mask数据
- 某个文档的图片和文字,并采取和Bert一样的方式进行Mask。
- 某个文档的图片和文字,并对某段文字或某个图片整个Mask掉,旨在强制模型学习“背诵课文“。
finetune模型类似图示
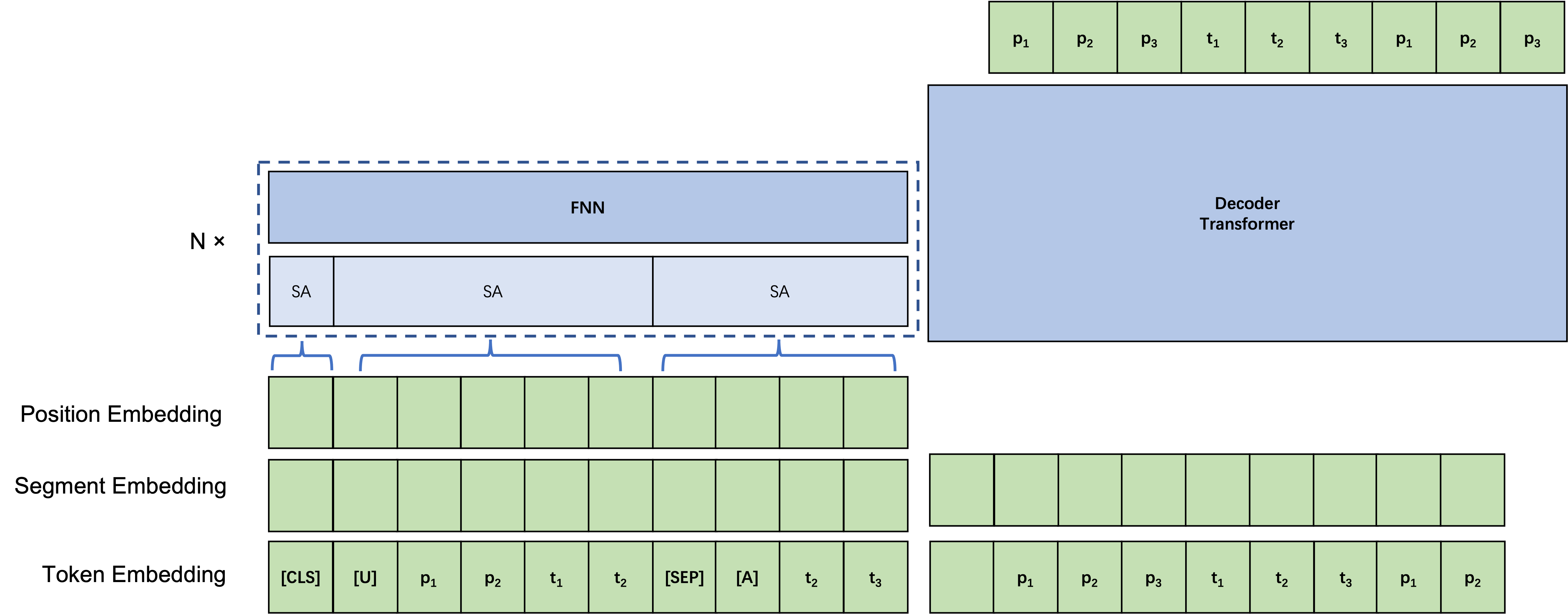
finetune
整体相当于Encoder-Decoder结构,Encoder阶输入背景知识[CLS]和某一条对话前所有的对话(包含User和Agent),并对User和Agent前面各自加上特殊标记[U]和[A],并用[Seq]标记隔开,同时,考虑Transformer复杂度为O(n^2),随着到对话的加长有可能Encoder阶段速度会越来越慢,因此本文引入双层Self-Attention机制,对每个句子单独做Inner-Self-Attention,然后对整个序列做Global-Self—Attention,从而大幅度降低序列长度。
对话质量的自动评价
当前业内针对对话系统的评价指标往往是和其他生成类任务相同都采用类似BLEU词重叠的方法,但是对于对话系统来说这些评判标准往往比较死板,甚至与人类评判相关性很差。基于知识的对话系统基本评价指标包含两个:其一是正确性,其二是和人类语言的相似程度。针对前者可以采取关键词匹配的方式,后者比较难解决,本课题拟尝试基于Gan的评价指标,在Gan模型中,Generator用于将隐变量编码为某一个概率分布,Discriminator用于判断该概率分布是否符合人类语言,因此理论上Discriminator可以用来当作指标,但该方案存在的问题是作为指标,本质上应当是固定的,而该方式不同研究者需要训练指标模型,因此不确定性较大。
MRC一般可以采用准确率、F1等,但文本生成的自动评价指标(如PPL)无法反映对话质量的好坏,而人工评价方法代价过高。我们需要一种代价低廉,自动评对话有趣程度、信息含量、一致性等问题的评价方式;
- 将文字、图片、视频等多模态资源作为外部知识加入到对话中,同时,各模态的存在形态也不尽相同,例如文字不仅可以表现为句子、段落,同时还可以表现为表格,相关数据集的数量和规模还有待提高;
- 终身学习问题。
对话系统还有一个和其他生成任务最大的区别,当User和Agent在对话的时候,User很有可能会在对话中添加背景以外的知识,我们希望在对话的进行中,模型能够持续地利用两者的交互进行自身的更新和优化,能利用已得到的“技能”融合不同结构的资源,这是本课题的另一个研究重点,即终身学习(life-long问题)。
该问题最大的难点是Catastropic forget,由于用交流的过程有时序,模型训练的数据顺序需要严格而不能打散, 判断神经元输出归一化后绝对值越接近0越不重要研究方法
本课题针对基于知识的多模态对话生成拟提出一种finetune方式,对多模态知识进行统一建模,同时设计了多种损失函数,针对对话生成阶段可能序列过长的问题,提出一种双层Self-Attention结构,

