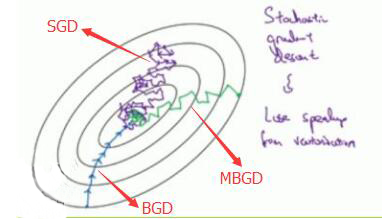
梯度下降一般常提到的有三种方式:批量梯度下降法BGD、随机梯度下降法SGD和小批量梯度下降法MBGD,下面依次介绍.
假设有$m$个训练数据,则参数$\theta$更新公式为:
批量梯度下降(Batch Gradient Descent,BGD)
参数更新公式为:
伪代码为:1
2
3
4repeat
{
公式(1)
}
即每次迭代都将$m$个训练数据全部计算一遍,用以更新参数.
- 优点:
1.一次迭代是对所有样本进行计算,此时利用矩阵进行操作,实现了并行
2.由全数据集确定的方向能够更好地代表样本总体,从而更准确地朝向极值所在的方向。当目标函数为凸函数时,BGD一定能够得到全局最优. - 缺点:
速度慢
从迭代的次数上来看,BGD迭代的次数相对较少。其迭代的收敛曲线示意图可以表示如下:
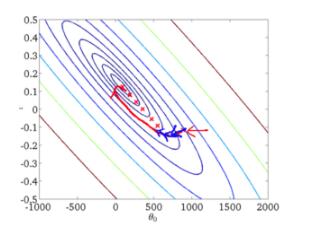
随机梯度下降(Stochastic Gradient Descent,SGD)
参数更新公式为:
伪代码为:1
2
3
4
5
6
7
8Random shuffle dataset;
repeat
{
for i=1,2,3...m
{
公式(2)
}
}
也就是不是同时使用所有训练数据,而是逐个使用每个训练数据。
- 优点:
1.由于不是在全部训练数据上的损失函数,而是在每轮迭代中,随机优化某一条训练数据上的损失函数,这样每一轮参数的更新速度大大加快。 - 缺点:
1.准确度下降。由于即使在目标函数为强凸函数的情况下,SGD仍旧无法做到线性收敛。
2.可能会收敛到局部最优,由于单个样本并不能代表全体样本的趋势
3.不易于并行实现。
从迭代的次数上来看,SGD迭代的次数较多,在解空间的搜索过程看起来很盲目。其迭代的收敛曲线示意图可以表示如下:
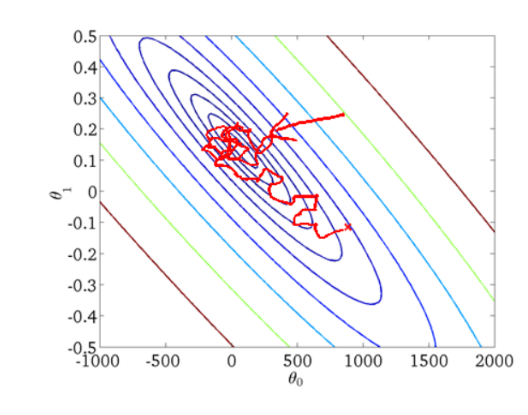
小批量梯度下降(Mini-Batch Gradient Descent, MBGD)
思想为综合BGD和SGD两种方式取中,伪代码为:
1 | repeat |
上诉代码中batchsize为10,即每10个算一个并行更新一次
优点:
1.通过矩阵运算,每次在一个batch上优化神经网络参数并不会比单个数据慢太多。
2.每次使用一个batch可以大大减小收敛所需要的迭代次数,同时可以使收敛到的结果更加接近梯度下降的效果。(比如上例中的30W,设置batch_size=100时,需要迭代3000次,远小于SGD的30W次)
3.可实现并行化.
缺点:
1.batch_size的不当选择可能会带来一些问题
三者对比图