词表征(word representation)和句子表征(sentence representation)方式总结
词表征(word representation)
one-hot encoding
不解释
Word Embedding
主要分为两类:Frequency based Embedding和Prediction based Embedding
Frequency based Embedding
- Count Vector
最简单的方式,将train用的N个文本按顺序排列,统计出所有文本中的词频,结果组成一个矩阵,那么每一列就是一个向量,表示这个单词在不同的文档中出现的次数。 TF-IDF Vector 比较好的介绍文章
TF是”词频”,IDF是”逆文档频率”.TF-IDF方法基于前者的算法进行了一些改进,它的计算公式如下:其中,$tf_{i,j}$(term-frequence)指的是第i个单词在第j个文档中出现的频次;而$idf_i$(inverse document frequency)的计算公式如下:
其中,1用来防止$n$为0,$N$表示文档的总个数,$n$表示包含该单词的文档的数量。这个公式是什么意思呢?其实就是一个权重,设想一下如果一个单词在各个文档里都出现过,那么$N/n=1$,所以$idf_i=0$,这就意味着这个单词并不重要。这个东西其实很简单,就是在term-frequency的基础上加了一个权重,从而显著降低一些不重要/无意义的单词的frequency,比如a,an,the等,很明显$n$越大$idf_i$越小,即所谓的逆文本。
Co-Occurrence Vector
直译过来就是协同出现向量。在解释这个概念之前,我们先定义两个变量:- Co-occurrence
协同出现指的是两个单词$w_1$和$w_2$在一个Context Window范围内共同出现的次数 - Context Window
指的是某个单词$w$的上下文范围的大小,也就是前后多少个单词以内的才算是上下文,比如一个Context Window Size = 2的示意图如下:
He is not lazy. He is intelligent. He is smart.
我们假设Context Window=2,那么我们就可以得到如下的co-occurrence matrix(共现矩阵):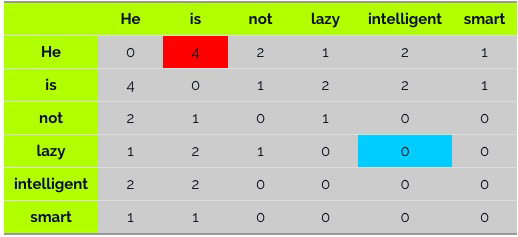
- Co-occurrence
Word2vec
Word2vec的直观直觉是两个用两个单词同时出现的概率来区分不同单词。
上面介绍的三种Word Embedding方法都是确定性(deterministic)的方法,而接下来介绍一种非确定性的基于神经网络的预测模型——word2vec。它是只有一个隐含层的神经网络,且激活函数(active function)是线性的,最后一层output采用softmax来计算概率。它包含两种模型:CBOW和Skip-gram.
Glove
Glove的直观直觉是单词同时出现的概率的比率能够更好地区分单词参考链接。比如,假设我们要表示“冰”和“蒸汽”这两个单词。对于和“冰”相关,和“蒸汽”无关的单词,比如“固体”,我们可以期望P冰-固体/P蒸汽-固体较大。类似地,对于和“冰”无关,和“蒸汽”相关的单词,比如“气体”,我们可以期望P冰-气体/P蒸汽-气体较小。相反,对于像“水”之类同时和“冰”、“蒸汽”相关的单词,以及“时尚”之类同时和“冰”、“蒸汽”无关的单词,我们可以期望P冰-水/P蒸汽-水、P冰-时尚/P蒸汽-时尚应当接近于1.
另一方面,之前我们已经提到过,Word2Vec中隐藏层没有使用激活函数,这就意味着,隐藏层学习的其实是线性关系。既然如此,那么,是否有可能使用比神经网络更简单的模型呢?
基于以上两点想法,Glove提出了一个加权最小二乘回归模型,输入为单词-上下文同时出现频次矩阵(共现矩阵):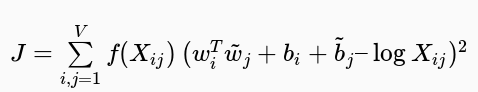
其中,f是加权函数,定义如下:J.png)

