生成模型
$\qquad$众所周知,神经网络是个判别模型,此处所指”生成模型”指的是功能性质,即利用神经网络生成我们需要的数据,比如对话生成/图像生成/语音生成。
$\qquad$试想,我们现在想生成一个图片,需要怎么做呢?
- 需要知道我们要生成一个什么样图片,比如我们想生成一个卡通头像
- 需要找到类似所需卡通图片的很多卡通图像
- 用2中的所有图像训练一个模型
- 给3中的模型一个输入,得到所需卡通头像
AutoRegression

自回归是一种Step By Step的方式, 相关论文有:WaveNet、PixelRNN、PixelCNN
优点:对对话/语音这类顺序明显的类别比较友好
缺点:
- 对图像而言,很难确定一个好的生成顺序
- 在inference阶段,当前步骤严重依赖前一步骤
- 慢
AutoEncoder

优点:
- 无需Step By Step,可以并行生成
- 生成数据更规则,一板一眼。
缺点:loss是对元素级别的监督度量,全局信息关注不足,因此模型泛化不够,两个非常接近的输入,可能输出天差地别。
举例说明:![]()
你认为左图和右图中哪个更相似呢?很显然是B,但是它和输入图像差了5个pixel,而A只差了2个pixel,而按照AutoEncoder的方式训练,模型认为和A更相似。
Variational Autoencoder
$\qquad$现在想想,我们训练了这样一个模型,要怎么用呢?最简单的用法是把$Eocnder$编码后的向量(latent vertor),保存下来,用的时候在用$Decoder$生成,但这仅仅是压缩的作用,显然大材小用了,我们其实想要的是,对于$Encoder$编码后的向量所符合的分布中,任意取一个向量都能产生合理的图片。 这样我们就能只保存$Decoder$和分布相关参数,从而产生出我们没见过的图片。很显然,现在的问题是,我们根本无法控制$Encoder$的输出分布,也就无法判断某一个向量是否符合该分布,这种情况下$VEA$出现了。
$\qquad$ VAE 其实最理想的控制$Encoder$分布的方式是模型训练好之后,用所有的训练输入通过$Encoder$各自得到一个向量,然后用这些向量得到分布,但是该方法几乎不可能,我们常用的方式类似最大似然,假设一个分布,然后用数据计算参数,VAE的思想是,对$Encoder$添加约束,强制使其输出符合高斯分布,那么模型训练好之后就能从该高斯分布中随机取向量生成没见过的图片了。
$\quad$说起来简单,但实际上VAE是一个实现起来简单,但是理解起来很复杂的模型,后续专门写一篇,这次就作为简单理解。
GAN
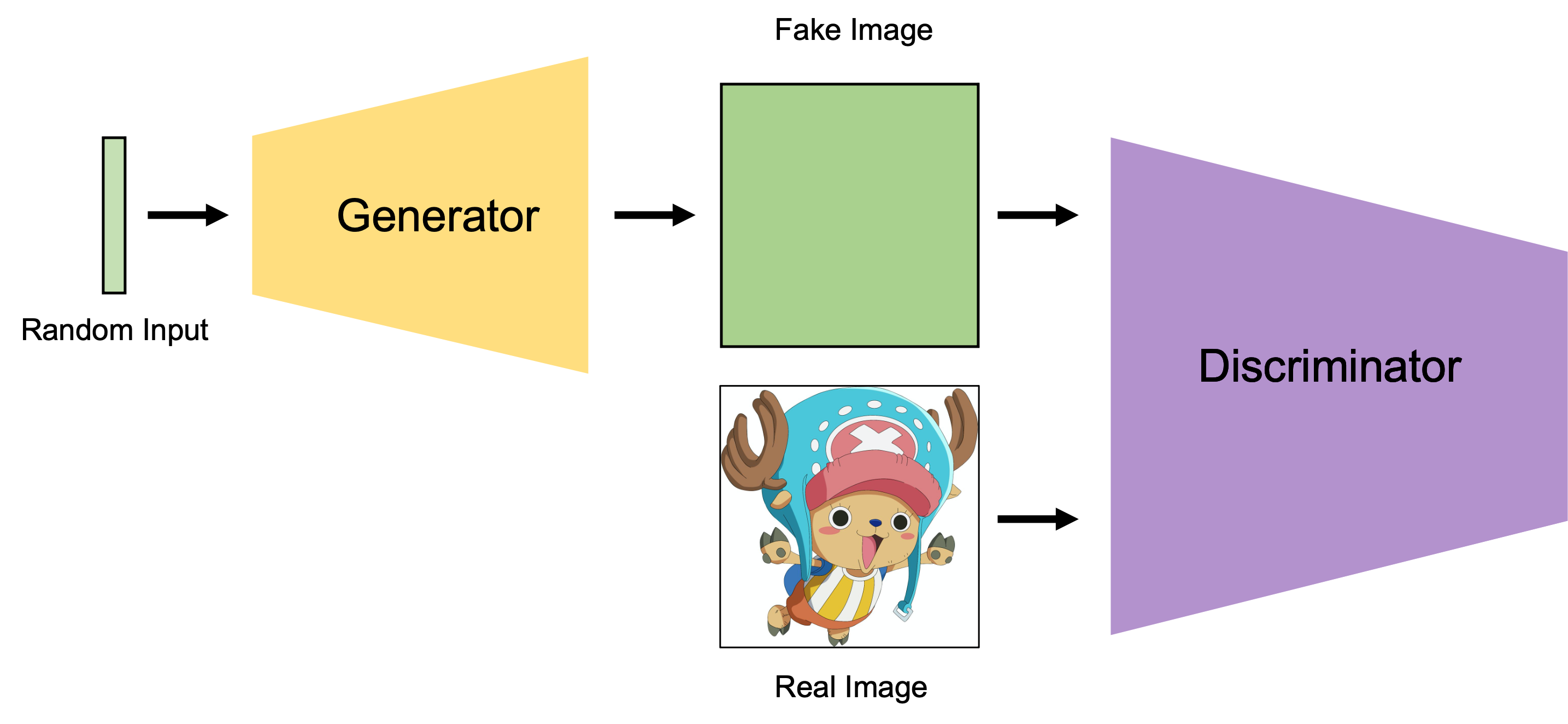
- 从任意分布(如高斯分布)sample一个向量,输入Generator得到和所需图片相同size的输出
- 把1中的输出当作副样本,从训练数据中sample一个正样本,以二分类的形式训练Discriminator(freeze Generator)。
重新sample一个向量,输入Generator得到和所需图片相同size的输出,将其当作正样本输入Discriminator,计算loss 训练Generator(freeze Discriminator)
上诉三个步骤是一个轮次。
这里面有两个问题:Generator可不可以自己学?
理论是可以,但操作起来不行,如果这样做的话训练应该是这样一个流程:
从任意分布(如高斯分布)sample一个向量,输入Generator希望得到和真实数据一样的分布,即$Generator$应该满足:这个很容易理解,其实就是一个最大似然估计而已,但是很显然,$G(x_i)$我们无从得知。因为我们在概率论中计算这种情况都是假设$G(x)$是某种分布再计算,但是神经网络非常复杂,根本不是假设某个分布就能做到的。
- Discriminator可不可以自己学?
可以,如果这样做的话训练应该是这样一个流程:
首选sample一部分真实图片(正样本),随机初始化一些乱七八糟的图片(负样本),训练Descriminator,然后在求:令$x$为负样本在反复计算,知道收敛。 但问题是,公式(2)的计算也是很困难的。
GAN损失函数
论文中给出的损失函数是这样的:
论文中说,这个损失函数相当于$JS(p_{data}(x)||p_g(x))$,现在我们来证明一下。
首先需要意识到的是,$p_{data}(x)$、$p_g(x)$、$p_z(z)$是三个分布,指的是括号中变量的概率值,即可以看作一个函数。
我们对(3)中的第二项进行积分换元:
假设$G(x)$是个可逆函数(该假设一般不成立),则有:
因此,带入公式(3)中可得:
固定$G(x)$,让$D(x)$最大,令偏导为0:
最终可得:
因此,当$G(x)$固定时,$D^*_G(x) $最优解为公式(7)
而又有:
这就得到了GAN损失函数和JS散度的关系。
实例代码地址
Flow
$\qquad$ 无论哪种生成模型,我们努力想要得到的无非两个东西,其一是$latent \quad vector$的分布,其二是$Generator$,这两者是成对的。基本原理就是如果从$latent \quad vector$输入$Generator$得到的结果分布$p_g$和真实数据分布$p_{data}$一致,那么我们就认为这个$latent \quad vector$的分布和$Generator$足够好.
$\qquad$ 在这个原理下就引入了两个难题,其一众所周知,数据分布是无法准确得知的,因此一般我们解决方式是强制固定分布来训练$Generator$,其二是如何衡量$Generator$的输出$p_g$和真实数据分布$p_{data}$足够近呢?两个分布距离一般用$KL$散度或$JS$散度,但不知道具体分布同样无法计算,$Gan$的方案是引入$Discriminator$,最后发现,诶,这个损失函数和$JS$散度等价,大功告成。
$\qquad$ 而Flow说,GAN算不了分布,我能算。
$\qquad$ 对于一个$Generator$而言,我们希望让其输出和真实数据分布越接近越好,即公式(1),但难点是$p_g(x_i)$未知,Flow的思想就是想方设法把这个分布用公式表达出来。
其基本原理是这样的,假设$z \sim \pi(z)$,经过$x=f(z)$函数的映射,得到$x\sim p(x)$,其中$f(z)$是可逆函数则有:
详见此处,所以,我们可以把公式(1)改写为:
那现在的问题是,我们无法保证一个普通的神经网络是可逆的,因此$G(x)$需要精心设计,而不能随便用。
首先需要确定的是,这里的雅可比矩阵必须是方阵(否则怎么算行列式?),因此$z$和$x$必须同形,flow的基本结构称为coupling layer,如图所示:
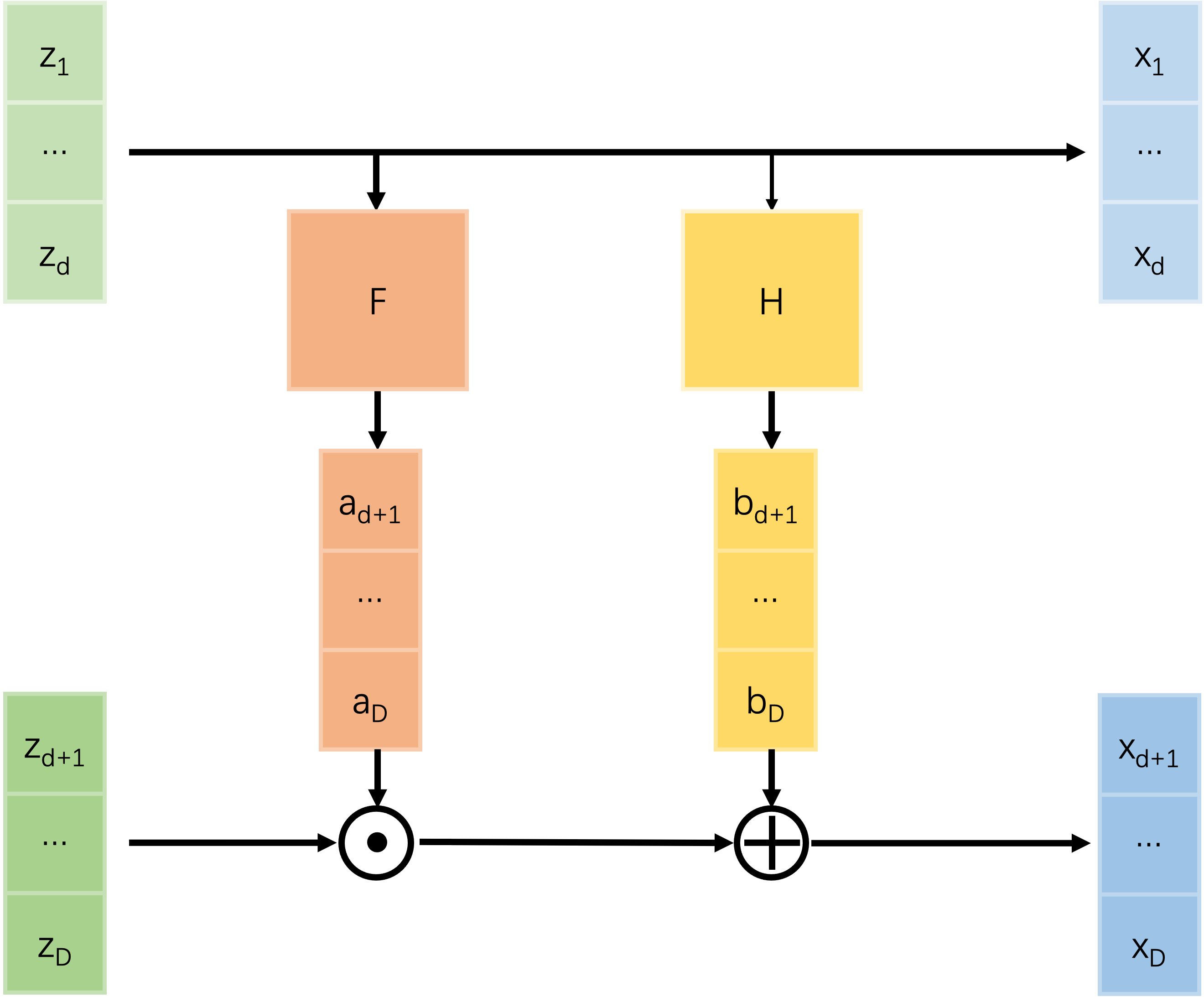
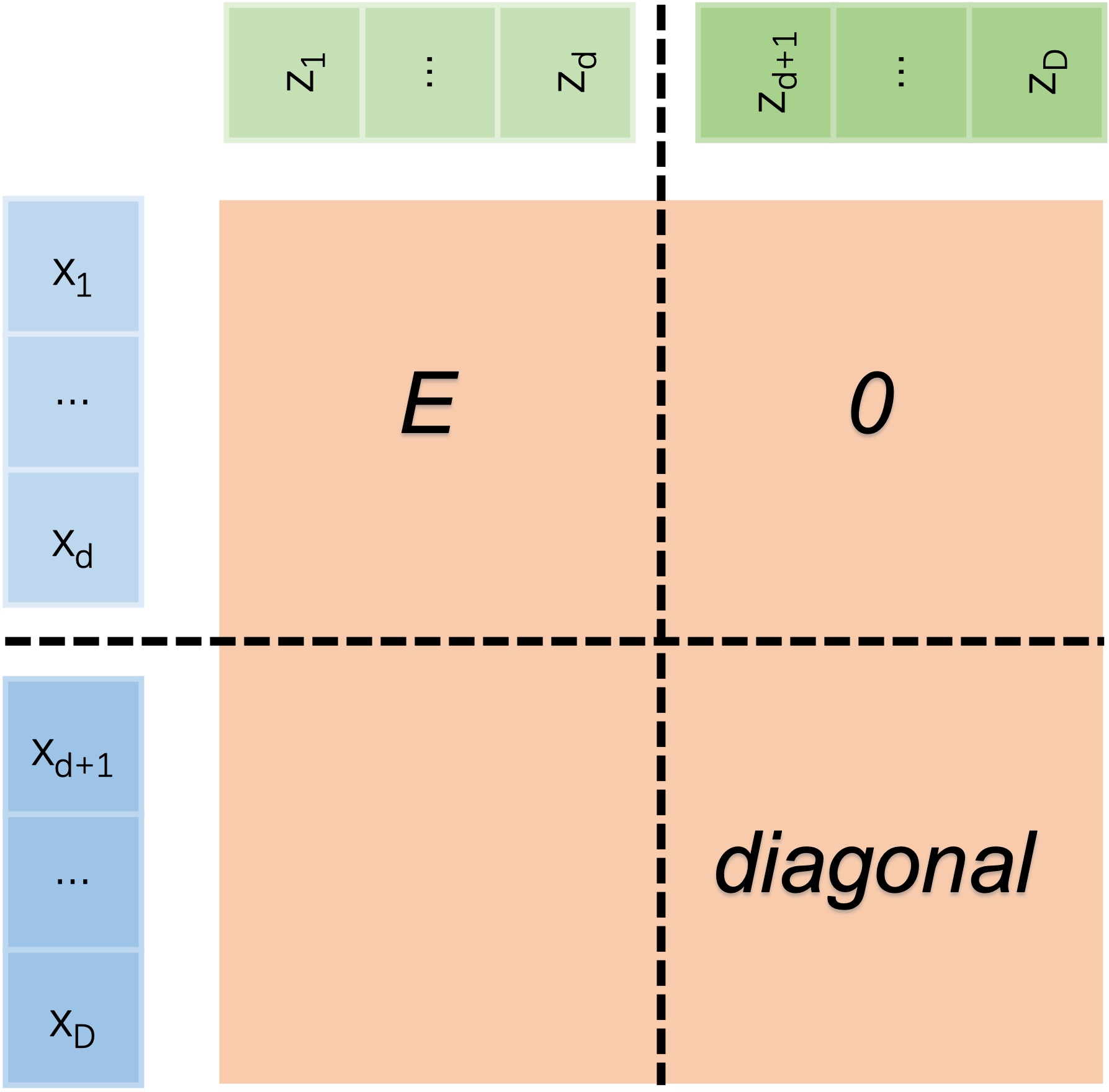
左上角是单位矩阵,右上角是0矩阵,左下角无关紧要,右下角是对角矩阵。
因此$G$即为所求。

