BLMO是为了解决word2vec的一词多意而诞生的,比如“苹果”这个词,在word2vec中的词向量是确定的,无论语境是在讲水果还是手机,但是在BLMO中单个词的词向量是随上下文而变化的,即动态的词向量,原理就是在将词转化为此向量的时候让其通过一个网络,得到上下文信息,然后在将其与预训练的静态词向量加权获得真正要在下游任务使用的词向量。
基本框架


也就是说,在我们想进行一个下游任务比如文本分类,本来需要输入是预训练的词向量,直接将词向量输入模型即可,但是现在我们需要首先将输入词通过BLMO,得到新的词向量,然后在将其输入模型.
使用方式
源码部分解析
主要模型都在bilm/model中的BidirectionalLanguageModelGraph类.
1.word embedding or word_char embedding:1
2
3def __init__(self, options, weight_file, ids_placeholder,
use_character_inputs=True, embedding_weight_file=None,
max_batch_size=128):
对应_build函数
1 |
|
也就是说无论输入的是字符还是词,
use_character_inputs=True都默认使用char_embedding,一般都这样设置,_build_word_embeddings虽然写了,但是似乎就没什么作用(按道理应该是用该函数得到预训练的词向量然后和上下文词向量加权,但是代码中似乎并没有用它).
2.构建word_char embedding
这部分代码的输出要输入LSTM,应该是总体模型中最复杂的一部分,代码较长,只挑重点部分(函数_build_word_char_embeddings):
1 | ... |
这部分是得到
char_embedding的代码
下面这部分代码是卷积char_build_word_char_embeddings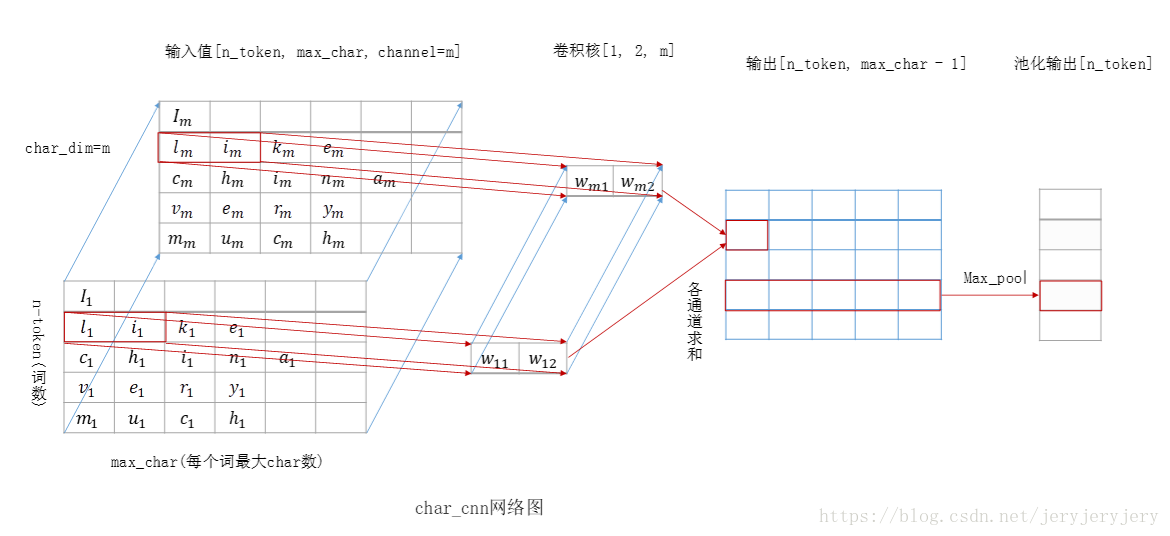
输入是[batch_size,n_token, max_char, char_dim],batch_size表示句子数量,n_token表示一个句子单词数,max_char表示一个单词字符数,char_dim表示字符向量维度。
卷积核size为[1, n_width, char_dim,char_dim],卷积得到的结果为[batch_size,n_token,max_char-n_width+1,char_dim]。上图是对[1, n_width, char_dim]卷积的结果,然后将m各卷积核得到的结果contact起来,然后下一步经过highway层和project层,这两层可选,且前后维度完全相同。

